In this part I want to talk first about the CPU bug I had, and how I fixed it, then I want to discuss the C64’s memory mapping system, and how I deal with rapid paging on a per instruction basis.
So the problem with CPU bugs, is that you have very subtle bugs that only show themselves on the 10 or 20 thousandth instruction. Now, you can either step through everything using a 6502 debugger (which you’d also have to write and debug first!), and see at what point it goes wrong, or you can think outside the box a little…
Now, in the past I’ve either written a test suit, or built in a 6502 debugger – or both. But this is very time consuming (not to mention a pain in the bum). One thing I DO have that helps though, is a working PC emulator. So Russell suggested than I simply dump registers out every instruction to a log file, then do a file compare on them both. If you remember the previous post I talked about looking up an opcode, then executing it, looking up the next one and so forth….then you’ll realise – like I did, that I can easily print a line of text every time I execute an opcode. So…doing the PC one first, I set about doing a very simple logging function…..and that’s when my troubles really started.
Simply printing a line of text to a file every opcode means opening/seeking/writing/closing every time I write a LOG line out, and with hundreds of thousands of lines (I ended up with 858,863 lines to be more precise), it was never going to be quick. I left it running for a while, and got hardly any distance at all. It was pretty clear I’d need some kind of memory cached log file.
So, I created a memory buffer of about 32K, and I wrote strings into this, then flushed it to a text file every time it filled up. This worked great on the native PC version, and I was soon rewarded with a 40Mb file looking something like this….
PC=FCE4 A=00 X=FF Y=00 F=80 SP=FF Line=000000
PC=FCE5 A=00 X=FF Y=00 F=B4 SP=FF Line=000001
PC=FCE6 A=00 X=FF Y=00 F=B4 SP=FF Line=000002
PC=FCE7 A=00 X=FF Y=00 F=B4 SP=FF Line=000003
PC=FD02 A=00 X=FF Y=00 F=B4 SP=FD Line=000004
|
| more....
|
PC=E5D4 A=00 X=00 Y=0A F=32 SP=F3 Line=0D1AE9
PC=E5CD A=00 X=00 Y=0A F=32 SP=F3 Line=0D1AEA
PC=E5CF A=00 X=00 Y=0A F=12 SP=F3 Line=0D1AEB
PC=E5D1 A=00 X=00 Y=0A F=32 SP=F3 Line=0D1AEC
PC=E5D4 A=00 X=00 Y=0A F=32 SP=F3 Line=0D1AED
PC=E5CD A=00 X=00 Y=0A F=32 SP=F3 Line=0D1AEE
PC=E5CF A=00 X=00 Y=0A F=12 SP=F3 Line=0D1AEF You might notice that I print HEX numbers. I do this simply so that every column is the same width all the time, since decimal numbers would make for some very wobbly lines, but as it now stands, it’s easy to compare a line above to a line below and so on. Also while the “Line” isn’t relevent to the CPU, when you do a simply “fc.exe <file1> <file2>” it only tells you the text that’s different – not where it is. This way, when it displays a lines thats different, I can also see what line its on, and simplyt search both text files for “Line=??????” to find the correct location.
Now if any of these changed, I could look up a C64 rom disassembly and then find the instruction that was failing, and fix it. Of course… now I would have to make a GML version of the cached log file, and hope it was at least as close to being as quick as the C++ one… Buffers seemed like the way to go as I can create a large buffer, and fill it with strings, and then flush it when I need to. Unfortunately I quickly discovered that buffers can’t append to a file, but as luck would have it file_text_open_append() can! So using a mix of buffers and text files (and a little fudge because of how strings write to buffers), I came up with a very handle little function that does large-cached log files in GML.
Here’s the function below…..
/// Log( _text )
s = argument0;
if( LogIndex>31000 )
{
LogSize+=buffer_tell(LogBuffer);
buffer_seek(LogBuffer,buffer_seek_start,0); // seek back to start of the buffer
var txt = buffer_read(LogBuffer,buffer_string); // read the text from the buffer
buffer_seek(LogBuffer,buffer_seek_start,0); // seek back to the start of the buffer
var f = file_text_open_append("myfile.txt");
file_text_write_string(f,txt);
file_text_close(f);
LogIndex=0;
}
buffer_write(LogBuffer, buffer_string, s);
buffer_seek(LogBuffer,buffer_seek_relative,-1); // seek back to the start of the buffer
buffer_write(LogBuffer, buffer_u8, 10);
LogIndex+=string_length(s);
linecount++ You obviously have to create a 32K buffer called LogBuffer, but aside from that… You’ll probably have to add a general log_flush() for when you exit the program, but I had no need of that.
Handy function this, although it should be noted this is based on an upcoming version of GameMaker: Studio. The current version has a limit of 4090 characters, and if you try and output more than that via file_text_write_string(), it’ll write rubbish to the stream. This has since been fixed, but if you want to use this function above just now, then lower the 31000 to 3700, and you should be fine.
I can then call this from my process loop like this….
Log( "PC="+Hex(_PC,4)+" A="+Hex(_A,2)+" X="+Hex(_X,2)+" Y="+Hex(_Y,2)+" F="+Hex(_F,2)+" SP="+Hex(_SP,2)+" Line="+Hex(linecount,6) );So…. once I had this, I was able to pin down that the error was in both the ADC and SBC instructions. It turned our that the way overflow flag was being calculated had changed from C++ to GML. This was because C++ has a “signed char” type (which is a signed byte), and I didn’t have one in GML so I took the cast away. However, it was needed so I’ve ended up having to do the same casting manually in GML. This slows things down a fraction, but nothing terrible, and it needs to be done, so there’s no point in crying about it.
There are still CPU bugs in there, but they’ll be harder to find now as only the start up sequence is consistent enough for this logging method. I could probably trigger it on the PC hitting an address as well though, that would probably help.
The next thing I want to discuss here is the C64 memory mapping.
Before getting into this, I want to quickly talk about arrays and grids. When I started this project and needed 65536 memory locations, my natural instinct was to create an array with 65536 slots in it, then use the new accessor [@…] so I could modify the underlying array directly, but after a little bit of testing, it turns out the [@…] accesor is a bit slower than grid access. So while Array[…] reading is slightly faster than grid reading, grids win out because grid writing is significantly faster than array writing via [@…]. Because of this, I have opted to use a 1 dimensional grid instead of an array by creating my memory pool like this pMemory = ds_grid_create(65536,1). This means you’ll be seeing lots of blah[# index,0] calls, which is the grid accesor, and 0 is our 1D row access.
The upshot of this, is if you need to read/write a lot, grids are quite a bit quicker, but if you only need to read, then you should stick with arrays. This is fine, and means most of our lookup tables can stay arrays (as we don’t write to them), while our system memory should be grids. One last point I’d like to make about grids, is that they also make a brilliant substitute to structures. We all know GameMaker’s lack of structures is a pain, but using grids and the accessors make it less so. Take a look at this C/C++ struct for example..
struct SBaddieData
{
int baddie_x;
int baddie_y;
int baddie_shape;
int baddie_colour;
int baddie_path;
int baddie_bullet_count;
};Up until now, I’ve either used an empty instance to store these, or multiple arrays (baddie_x[index] and baddie_y[index] etc.). While instances aren’t terrible, it’s still a bit of a waste – even if you deactivate them, your burning memory. Using grids and Macros/enums gives a pretty good alternative.
/// CreateBaddies()
pBaddie = ds_grid_create[BADDIE_STRUCT_MAX, MAX_BADDIES];
for(var i=0;i<MAX_BADDIES;i++)
{
pBaddie[# BADDIE_X, i]=-1;
pBaddie[# BADDIE_Y, i]=-1;
pBaddie[# BADDIE_SHAPE, i]=-1;
pBaddie[# BADDIE_COLOUR, i]=c_white;
pBaddie[# BADDIE_PATH, i]=-1;
pBaddie[# BADDIE_BULLET_COUNT, i]=0;
}
All we then need to do is make either an ENUM or MACRO setting BADDIE_X to 0, BADDIE_Y to 1 and so on, and we’re good to go! Knowing access to these is pretty fast, this gives us and easy to use array of structs – which I love.
With that dealt with, lets talk memory! The Commodore 64 is famous for having 64K of RAM, but it also has ROM, IO and Character data mapped in as well. You can see how – and where things are mapped in this diagram from the C64 manual
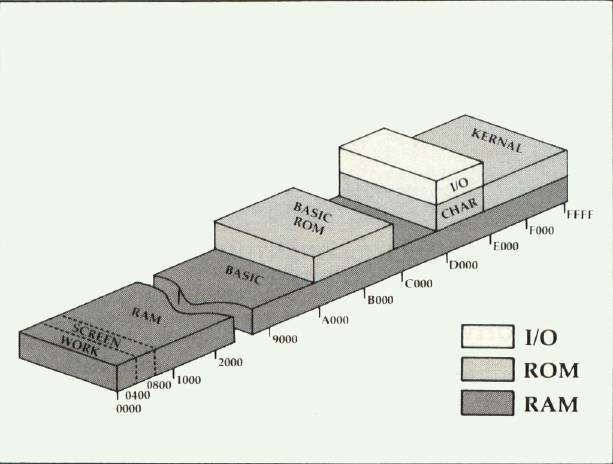
Now, while the CPU is reading bytes to execute, it also gets the correct data via the memory mapping system, and I have to do the same thing. The problem is, putting in lots of IFs into the GETABYTE() function to check what’s paged in and what’s paged out, before getting anything from memory, means it’ll just grind to a halt. Address $0001 holds the mapping and it can be one of 8 values, but it’s also based on the actual address being accessed. So I create a table using the top nibble (4 bits) of the address, and the 3 bits of the memory mapping register – giving 128 different values. Within this table I store references to the pMemory, pROMs and pCharacterSet arrays. The pROMs array is a mix of iO registers, and the BASIC and KERNAL rom.
So, whenever I now call GETABYTE(), I can get the correct array by simply getting the top nibble of the address and ORing it with the proper bits from location $0001. I can then return pMem[ _PC++] to get the byte. This speeds up general memory access considerably. Heres the current GETABYTE() fuinction…
// Assume we NEVER increment across from $FFFF to 0... save bet really.
var pc = _PC++;
if(pc<$a000){
return pMemory[# pc,0];
}
var pMem = pLookUp[((pc&$f000)>>9)|Location1 ];
return pMem[# pc,0];
Since I use pMemory[# $0001,0] so often, I remember this value in a variable so I don’t have to keep looking it up in the grid all the time. I only need to check and set it when the CPU does a Poke($0001,??). This gives a pretty sizable speed bump.
Functions like GETABYTE, GETAWORD, Peek() and Poke() do have a couple of fast paths in them though – just to help out. If the address is less than $A000, then it’s always going to be reading from pMemory, and never funny paged stuff or IO registers. With this in mind, I can simply check the address and if it’s <$A000 I can now just return it without any messing around.
Now we have a basic mapping system, what about the IO registers. Well in this case, I’m actually free to decide where I want to store them, as these are always special cased inside the Peek() and Poke() functions. So I decided that these will ALWAYS reside in the pROMs memory array, and inside Peek and Poke functions it checks the banking register, then does a simple switch() on the address if it’s within the pROMs area, so that it can specialise some of the memory locations – like this….
if( (address&$f000) == $d000 ){
switch( address ){
case $d011:{ // blah code here...
break;
}
case $d012: //blah code here....
break;
case $d014: //blah code here....
break;
case $d019: //blah code here....
break;
case $d01a: //blah code here....
break;
case $d01b: //blah code here....
break;
default:
pROMs[address]=value;
}
}Now these aren’t all of them… but it gives you the idea. Many just fall through and get stored, but some have to reset things. For example writing to the raster interrupt read register, also clears it. So $D019 (the VIC interrupt status register) does a little more work, while writing to a sprite colour – well, that just stores the sprite colour in the register, so it can fall through to the simple store value. Peek() has a similar function, although it has a different set of “important” registers. One of the quirks of hardware registers, is that you can get differernt values reading or writing. The guys that make hardware see no real reason to always make it mirror back what you’ve just written, so often make the read function of a register is totally different to the write function. It’s not something you care about when writing for the actual machine, but it does make writing an emulator for one more interesting.
What this now means, is that emulated instruction can access our pretend machines memory and get the proper IO registers, RAM or ROM depending on how it’s been setup to page – just ike it would on a real machine.
So there you go…. fixed a couple of nasty bugs, and implemented the RAM/ROM/IO paging efficiently. In the next part, I’m going to discuss some of the early screen rendering systems I did so I could see what the hell I was doing, and how I started to attempt to get something more accurate, but without slowing anything down.