Now that I had everything setup and running, I needed an easy way to develop, and clearly, typing on the machine itself, wasn’t going to cut it. The line editor on BBC basic was bearable back in the day, simply because that’s what we were used to, but these days – nope, that’s not something I can live with.
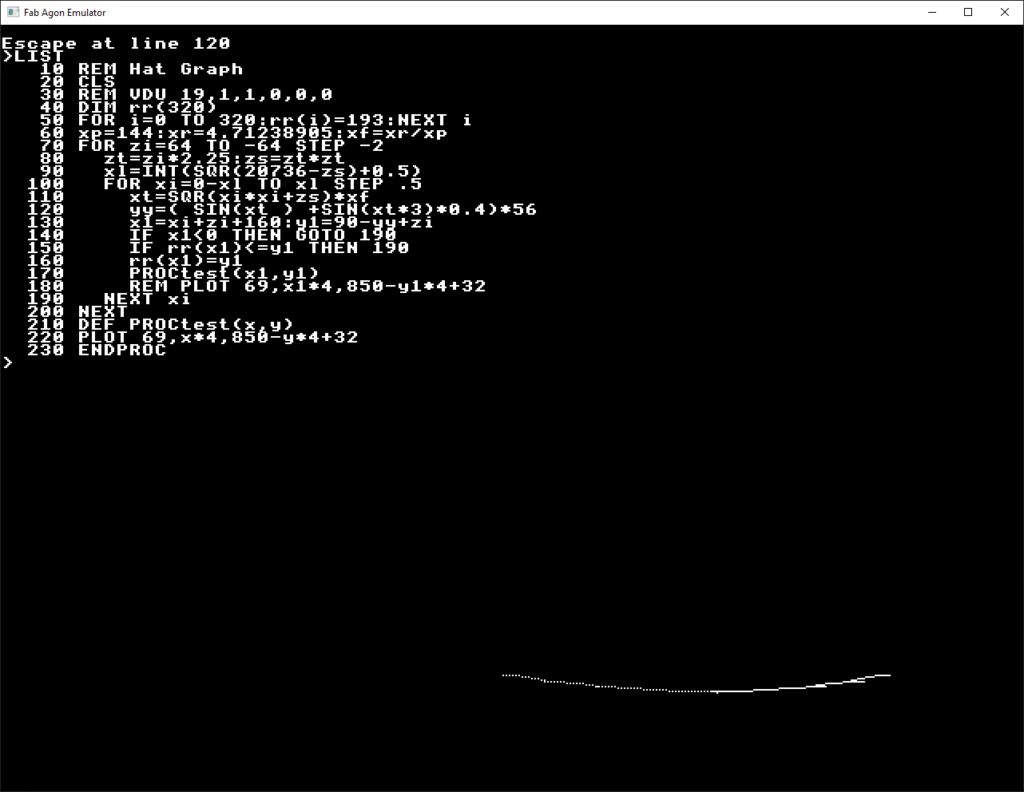
So the first thing was to take a look at one of the basic files on disk, and see what the format was like. I was pleasantly surprised to see it was plain ASCII – line numbers and all! It turns out that the machine can load tokenised or plain text, and if it’s plain text, it’ll tokenise it on load. The reason apparently was so that code could be posted in source control and viewed – and understood easily, and this was a great idea, and brilliant for me.
Because of this, the first thing I wanted to do, was ditch those line numbers.
This is pretty simple when you think about it. Each text line in a file, is simply another line number – using whatever increment you want. So I started out by creating a new C# program that read in a text file – the program above, but without line numbers. Then I looped through them and added a number to the start of the line, incrementing by 10 each time.
So is that job done? Well, not quite.
The next thing I hate, was having to have all the keywords in uppercase. This is again a product of the history of the language. Back in the day, we all coded in upper case, that was how the machine booted up, and that’s what we typed in, so it was fairly natural. But now, we work in lower case, and having all upper case text is just painful to read, and swapping windows for other programs etc means having to swap caps lock on/off etc. and that would be error prone.
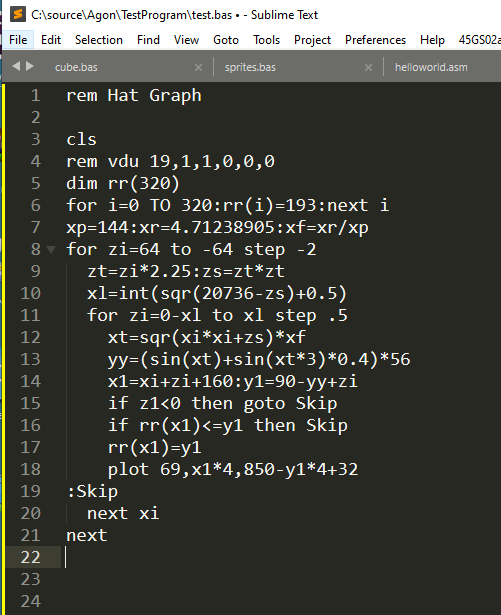
Comparing the lower case version here, to the uppercase one above, it’s instantly more readable. The other thing I needed to do was add labels for goto‘s. Because I’d taken away line numbers, if you needed to goto somewhere, you had no idea of the line number that would be generated.
I did this by using a colon “:” as the first character in the line, followed by a label – and that’s the only thing on the line. So I first pre-scan the file, and define the line numbers the labels will appear on, then when looping over the file, if I find that label anywhere, I replace it with the line number. This is just like assemblers do using EQUs etc, so it’s pretty simple.
But what I needed to do all this, is a parser, something that will read the file and allow me to find these labels – and keywords, and let me change them easily. Now, you can do a full on lexical processor like assemblers and compilers use – which take ages to write and get working, or I can simply look for “words” that are surrounded by spaces or symbols. This is about as dumb a parser as you can get, but it’ll work great for what we need.
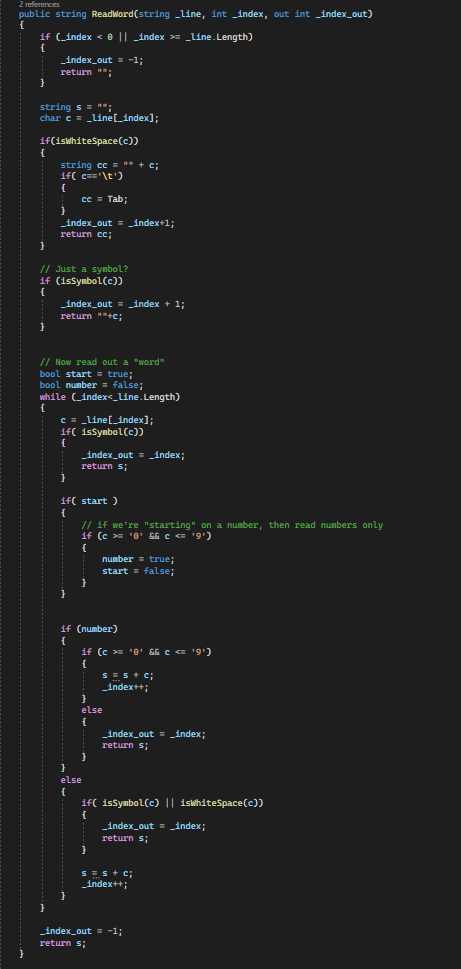
This is the core of the tool, it’ll read a line and return individual spaces, symbols, numbers or “words”, and I loop over this outputting everything as it comes, and occasionally replacing things.
So now when I read something like “for i%=0 to 10 step 5” I get a sequence of “for“,<space>”i“, “%“, “=“, “0“, <space>, “to“, <space>, “10“, <space>, “5“. I can then look up each word I get back, and see if it’s in the list of keywords. “for” will get found, but “i” won’t. This means “FOR” is returned as a replacement, but “i” stays the same – same for “to“=>”TO” and “step“=>”STEP“.
As I said, really simple.
What this means, is I can now write lovely source, and have this program output a “runnable” code at the press of a button – or a run of a batch file to be more precise.
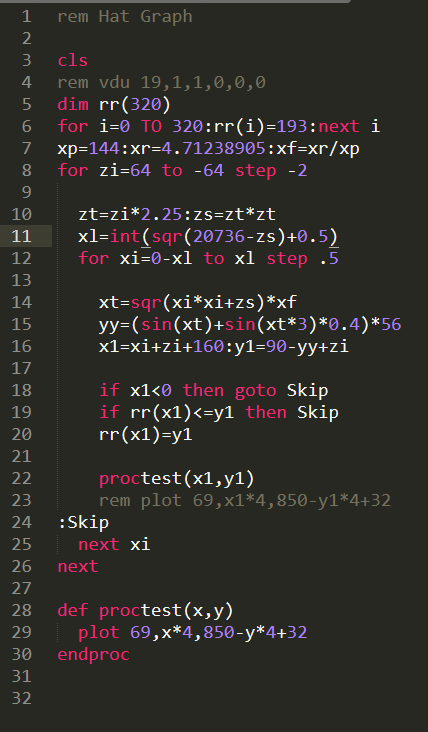
So this is what I end up writing, and as you can see, its far, FAR more readable. One of the other benefits of this tool, is that I can drop REM statements, and it’s really simple. While looping over the “words” in a line, if I detect a word “REM“, I simply stop outputting, and if the line is empty, I skip it. This packs the source down, making it quicker – and smaller, because REMs slow your program down..
You’ll also notice the lovely colouring. There’s a great Sublime Text (my editor of choice) Z80 plugin, that colours the text and helps with builds etc, so I copied that and hacked it into an Agon plugin that colours the text and makes it pretty to look at. This took way longer than it should have, as I struggled to get the build system working, but I eventually got it going, and now I can simply press F7 in Sublime Text, and it’ll convert the source, copy it over, and spawn the emulator, which autoruns the code.
It’s that simple. F7, run, check, done.
This fast turn around is vital to development. Having to copy code to an SD card each time, is a killer of dev time, so having a good emulator, and build environment is crucial. Longer term, I could output a tokenised binary file, but I don’t need that just now, so here we are.
These tools will go up on my GITHUB for everyone when I get time, and even though the source tool is simple, I find it invaluable. I couldn’t sit and type on the machine, it’d be way too slow.
Next time, I’ll start actually trying to write a simple Lemmings demo….