So the thing about BASCI is that it’s interpreted. This isn’t a surprise of course, it’s been known since the ZX80/81 days. But how does it work? Well, as you type in a command such as PRINT or FOR, the editor looks these up using a slow text search, and then stores a byte token instead. This means when running the program, it reads the byte, and looks up a table, and jumps to a function – more or less.
So that’s great for keywords, but what about variables? well these can be anything, so you can’t simply look them up and tokenise them. Because of this, variables are stored as plain text, and looked up using a HASH table. What’s a HASH table? Well, simply put, the first letter of the variable is used as an index into a table and then there’s a list of all variables starting with that letter. What this means is if you’re variable “HELLO” then it only needs to look for that in a list of variables starting with “H“.
This is a pretty good speedup, but the real pain comes in the text searching. Every time you reference a variable, it looks up the list, and then text searches through that list. So if you have 3 variables “HELLO“, “HEAP“, and “HELVETICA“, and then we use the variable “HELVETICA” it’ll look up list list using the “H“, and then compare each letter of each word until it finds that variable.
So what does that mean? Well take this line….
10 HEAP = (HELVETICA*HELLO) + (HELVETICA-1)
This requires 4 variable look ups, possibly 9 string searches (based on the above string order) to execute even this simple statement.
So how can we fix – or at least minimise this? Well, in 2 ways. First the BBC has a “special” fast variable system, where the single letter variable “A” to “Z” are optimised and looked up directly. So that’s good. Secondly, we need to shorten all variables to be as short as possible, so that when BASIC looks them up, it has to do minimal string comparisons. This is what that would look like…
Here we can see even 2 letter variables can be sped up if you can rename them down to single letter.
So how do I do this? Well if you remember the program I have that generates line numbers, labels, and upper cases keywords, what I need to do is do a proper 2 pass process – like an assembler, by modify the “ReadWord( )” function to return more “complete” word/variable.
Once I have this, I can then store all these variable names in a list, and then run through that list allocating an increasing variable name, starting with “a“, “b“, “c“….”x“,”y“,”z“,”A“,”B“…..”Y“,”Z“, “AA“,”AB” and so on.
This means “HELLO” would become “a“, “HEAP” become “b” and “HELVETICA” becomes “c” and so on. One tweak I added was that if I use a single letter variable myself, then I pre-allocate this so that I can use these myself in a program if I know I need to optimise a specific area.
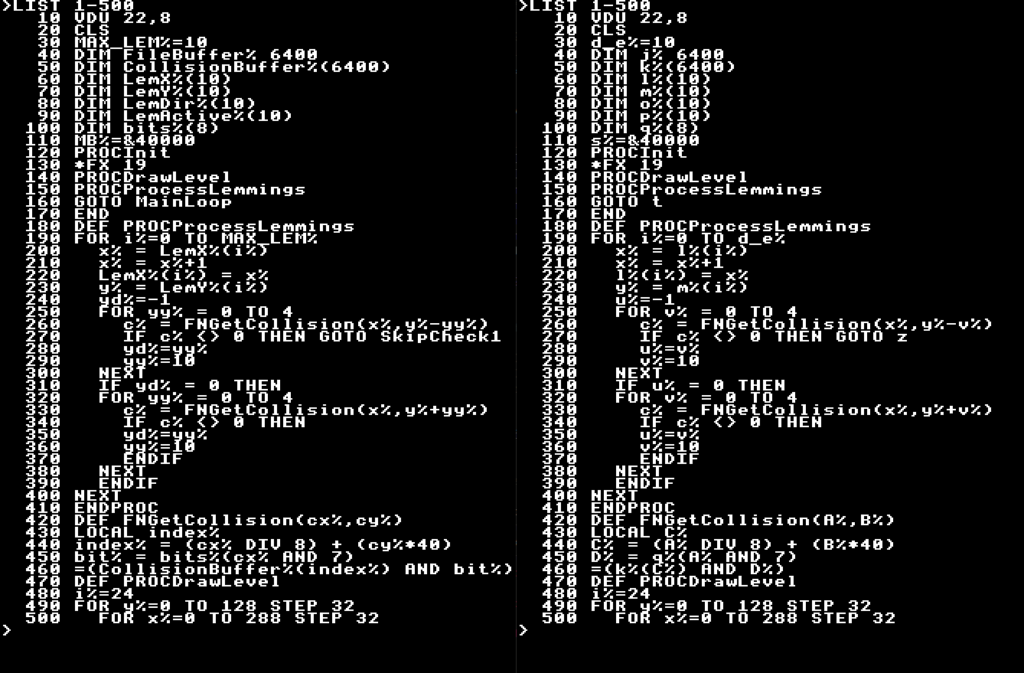
Here you can see some of my Lemmings code, with easy to understand – but long, variables. On the left you can see a compressed version. You can also see in the original I use variables like “c%” and those remain in the packed one allowing me to optimise specific areas.
Another nice side effect with pre-allocating variables, is you get a far, far better spread over the hash table. Variables like LemX%, LemY%, LemDir% etc would all live in the same variable list, making it long and slow each time I access then. Now think of what happens when they are renamed to “l%“, “m%” and “o%“. This means each of these is put in a different place in the table, and accessed much more quickly.
So there we go, my tool now has options to remove REM statements, and to compress variable names, allowing faster code.
All this goes into making a much nicer dev environment, removing issues that hinder production.
Now the only thing I need to try and fix now, is the lack of IF/ENDIF functionality. Stock BBC Basic only allows for single line IFs, and that’s a nightmare as you end up with goto’s all over the place.
So I’ll need to think about this one, but that’s next on my hit list….